§ 11. Простейшая модель игры двух лиц. Оптимальные стратегии. Одна схема управляемой цепи Маркова. Уравнение Беллмана
1.Пример. Игра с отгадыванием монеты. Рассмотрим следующую игру двух лиц. Один игрок прячет монету достоинством в 10 или 20 копеек, а другой игрок отгадывает, что за монета была спрятана. Если он называет монету правильно, то и получает ее в качестве выигрыша; если он ошибается, то платит 15 копеек. Каковы должны быть стратегии игроков при многократном повторении этой игры?
Пример. Тактика воздушного боя. Предположим, что авиация "красных" совершает налеты на некоторый пункт "белых". При этом каждое отдельное задание выполняется парой самолетов, один из которых несет бомбы, а другой является "прикрывающим". Предположим, что при атаке истребителей "белых" в 20% случаев выбывает из строя тот самолет, что летит первым и находится под защитой основных огневых средств второго самолета, и уже в 40% случаев выбывает из строя самолет, летящий вторым. Пусть истребители "белых" придерживаются той тактики, что атакуют лишь один из самолетов противника. Предположим, что главной боевой задачей для "красных" является бомбардировка объекта, а для "белых" - его прикрытие. В каком порядке должны лететь самолеты "красных" и какой из этих самолетов должны атаковать истребители "белых"?*
* (См. Дж. Д. Вильяме, Совершенный стратег (перев. с англ.), М., 1960.)
Эти и многие другие примеры укладываются в следующую простейшую схему игры двух лиц. Именно, каждый игрок может выбрать одну из двух стратегий, определяющих результат игры. При этом интересы игроков противоположны: то, что выигрывает один, фактически проигрывает другой. Такую игру можно описать с помощью таблицы (рис. 12), две строки которой соответствуют двум имеющимся стратегиям первого игрока, два столбца - двум стратегиям второго игрока, а стоящие в клетках числа характеризуют тот выигрыш, который получает первый игрок при выборе каждым из игроков соответствующих стратегий: если первый выбирает i-ю стратегию, а второй - j-ю стратегию (i, j = 1, 2), то выигрыш первого игрока равен vij, а выигрыш второго игрока равен - vji. Возникает вопрос, какими стратегиями должен руководствоваться каждый из игроков?
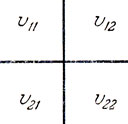
Рис. 12
На этот вопрос легко ответить в случае, когда, скажем,
Ясно, что, как бы ни играл второй игрок, наилучшей возможностью для первого является выбор 1-й стратегии, которая ему обеспечивает выигрыш, равный
При расчете на "умного" противника для второго игрока наилучшей является та стратегия j, при которой наибольший выигрыш противника является минимальным, т. е. та стратегия j, при которой
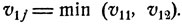
Описанный случай можно считать исключением. Как же поступать в более распространенной и вместе с тем более сложной ситуации, когда соотношения типа (11.0) не имеют места?
Поставим задачу более точно. Предположим, что первый игрок выбирает i-ю стратегию с вероятностью р1i, а второй игрок выбирает j-ю стратегию с вероятностью p2j. Распределения вероятностей 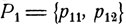 и
и 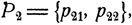 с которыми каждый из игроков выбирает соответствующие возможности поведения, называются смешанными стратегиями. При выбранных смешанных стратегиях естественно рассматривать средний выигрыш (первого игрока)
с которыми каждый из игроков выбирает соответствующие возможности поведения, называются смешанными стратегиями. При выбранных смешанных стратегиях естественно рассматривать средний выигрыш (первого игрока)
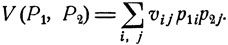
(11.1)
Предположим, что противник первого игрока выбирает наилучший ответ на каждую его стратегию , т. е. такую стратегию 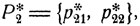 что выигрыш первого игрока при выбранной им стратегии Р1 является минимальным:
что выигрыш первого игрока при выбранной им стратегии Р1 является минимальным:
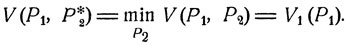
(11.2)
Если считать, что противник играет наилучшим образом, то при стратегии Р1 первый игрок получает средний выигрыш V1(P1), и наилучшей смешанной стратегией для него является то распределение вероятностей 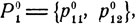 для которого
для которого
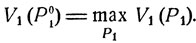
(11.3)
Совершенно аналогичные рассуждения применимы и на месте второго игрока, для которого наилучшей является стратегия Р02, обеспечивающая максимальный средний выигрыш при расчете на наилучшую игру противника:
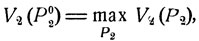
где
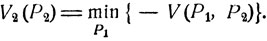
Найдем оптимальные стратегииР01 и Р02 для каждого из игроков. Рассмотрим функцию
При х = р11 и y = р21 эта функция численно равна среднему выигрышу первого игрока, когда выбираются смешанные стратегии и . Функция V(x, y) является линейной по каждому из переменных х и y, 0≤х, y≤1. Следовательно, при каждом фиксированном х она достигает своего минимума в одной из крайних точек y = 0 или y = 1:
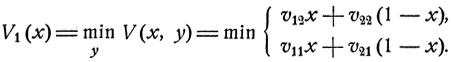
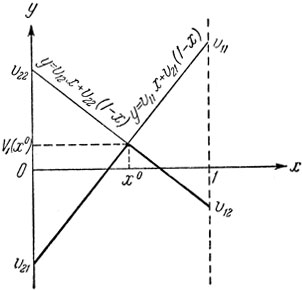
Рис. 13. min (v11, v12)≤max (v21, v22).
Как видно из рис. 13, график функции V1 (x) является ломаной с вершиной в точке x0, определяемой из уравнения
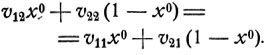
Имеем
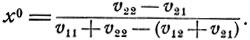
Точка х0 - точка максимума функции V1 (х), 0≤x≤1,- и есть та оптимальная вероятность p011, с которой первый игрок должен выбирать 1-ю стратегию.
Соответствующая смешанная стратегия обеспечивает наибольший средний выигрыш при расчете на самую лучшую игру противника. Этот выигрыш есть
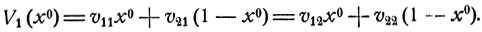
(11.5)
Каково бы ни было y, 0≤y≤1,
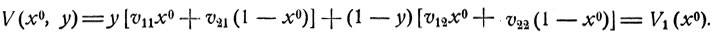
Видно, что при оптимальной вероятности р011 = х0, как бы ни играл противник (каково бы ни было y), первый игрок обеспечивает себе средний выигрыш V1 (х0). Если же он отклоняется от оптимальной стратегии р011 = х0, выбирая р11 = х, то при подходящем ответе противника, когда р21 = y есть y = 0 или y = 1, средний выигрыш первого игрока уменьшается до величины V1 (x).
Те же самые рассуждения применимы и на месте второго игрока, для которого оптимальное значение вероятности р021 = y0 есть
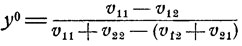
(оно получается из формулы (11.4), если игроков поменять местами, т. е. поменять местами индексы 1 и 2). Так же как и в случае первого игрока, при оптимальной вероятности р021 = y0 второй игрок обеспечивает средний выигрыш V2(y0) независимо от стратегии противника:
Отсюда, в частности, вытекает, что
Вернемся к рассмотренным ранее примерам.
Игра с отгадыванием монеты. Здесь следует положить
Оптимальное значение вероятности р011 = х0, с которой надо прятать 10-копеечную монету (в предложенной схеме это 1-я стратегия первого игрока), согласно общей формуле (11.4) есть
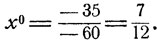
Оптимальное значение вероятности y0 = р021, с которой надо называть при отгадывании именно 10-копеечную монету (это 1-я стратегия второго игрока), согласно общей формуле (11.6), есть
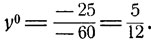
Таким образом, оптимальное поведение первого игрока состоит в том, что он с вероятностью 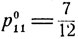 прячет 10-копеечную монету, а с вероятностью
прячет 10-копеечную монету, а с вероятностью 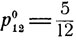 - 20-копеечную монету. Оптимальное поведение второго игрока состоит в том, что он с вероятностью
- 20-копеечную монету. Оптимальное поведение второго игрока состоит в том, что он с вероятностью 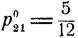 называет 10-копеечную 7 монету, а с вероятностью
называет 10-копеечную 7 монету, а с вероятностью 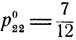 - 20-копеечную монету. При этом средний выигрыш первого игрока составит величину
- 20-копеечную монету. При этом средний выигрыш первого игрока составит величину
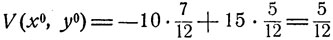
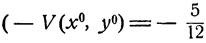
будет, следовательно, выигрыш второго игрока).
Видно, что описанная игра является невыгодной для второго игрока, даже при наилучшем поведении каждый раз проигрывающего в среднем 5/12 коп. Всякое же отклонение от этого наилучшего поведения при соответствующем ответе противника только приведет к большему проигрышу.
Тактика воздушного боя. В "игре" с бомбардировщиками "красных" и истребителями "белых" имеется две стратегии каждой из сторон: первым летит самолет с бомбами, первым летит прикрывающий, и атакуется первый самолет, атакуется второй самолет. Если определить выигрыш "красных" как вероятность выполнения боевой задачи - бомбардировки объекта, то следует положить v11 = 0,8, v12 = 1, v21 = 1, v22 = 0,6. По формулам (11.4) и (11.6) находим, что
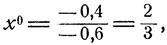
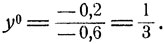
Видно, что для "красных" вовсе не будет наилучшим вариантом максимально обеспечивать безопасность самолета с бомбами, прикрывая его следующим за ним самолетом. Если так поступать всегда, то "белые" в ответ будут всегда атаковать первый самолет, в результате чего вероятность выполнения боевой задачи (вероятность того, что самолет с бомбами не выйдет из строя) будет равна 0,8. Если же, согласно оптимальной смешанной стратегии, поступать так лишь с вероятностью 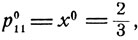 то при любой стратегии "белых" эта вероятность будет не меньше, чем
то при любой стратегии "белых" эта вероятность будет не меньше, чем
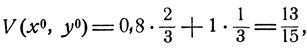
так что вероятность выполнения боевой задачи увеличивается на 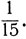
Оптимальная стратегия для "белых" состоит в том, чтобы атаковать первый самолет с вероятностью 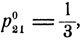 а второй - с вероятностью
а второй - с вероятностью 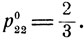
2. Будем условно говорить о некоторой физической системе, шаг за шагом меняющей свое фазовое состояние. Обозначим ε1, ε2, ... ее возможные состояния и ξ(t) - ее состояние через t шагов. Будем считать, что процесс эволюции системы, описываемый цепочкой переходов
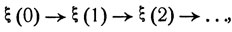
является случайным марковским процессом, причем вероятности рij перехода из состояния εi в соответствующие состояния εj зависят от некоторого управляющего параметра, так что, если система на каком-либо шаге находится в состоянии εi и в соответствии с этим наблюдатель выбирает определенное значение управляющего параметра d, то вероятности перехода на следующем шаге будут pij = pij(d). Совокупность возможных значений управляющего параметра d обозначим D.
Предположим, что задача регулирования такого управляемого случайного процесса состоит в том, чтобы привести систему в определенное фазовое состояние или в одно из состояний определенного множества Е. Поскольку течение процесса ξ(t) зависит не только от воли управляющего этим процессом оператора, но и от случая, привести систему в одно из фазовых состояний указанного множества Е, вообще говоря, можно лишь с некоторой вероятностью Р, зависящей от способа управления.
Предположим, что управляющий процессом оператор руководствуется следующей программой управления: для каждого состояния εi, куда система может прийти на некотором шаге n, предусматривается выбор соответствующего значения управляющего параметра d - для каждой пары εi и n свое значение d = d(εi, n). Вся программа может быть описана функцией d = d(x, t) от х = ε1, ε2, ... и t = 0, 1, ..., называемой решающей функцией. Если выбрана программа управления с решающей функцией d = d(x, t), то течение случайного процесса ξ(t) происходит таким образом, что при попадании на n-м шаге в состояние εi, на следующем шаге с вероятностями pij = pij(d), d = d(εi, n), осуществляется переход в соответствующие состояния εj, j = 1, 2,...
Ясно, что вероятность того, что система будет приведена в одно из заданных состояний, зависит от выбора программы управления, от выбора решающей функции d = d(x, t):
(Управление с решающей функцией d0 = d0 (х, t) называется оптимальным, если
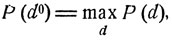
(11.8)
где max берется по всем возможным управлениям, по всем возможным решающим функциям d = d(x, t).
Рассмотрим следующую задачу управления случайным процессом ξ(t): через заданное число шагов п с максимально возможной вероятностью привести систему в определенное множество фазовых состояний Е. В этом случае
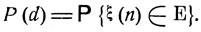
Пусть P(k, i, d) есть вероятность того, что при попадании на k-м шаге в состояние εi система за оставшиеся n-k шагов будет приведена в одно из состояний заданного множества Е (при этом считается выбранным некоторое управление d = d(x, t)):
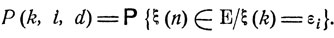
Имеет место следующее соотношение:
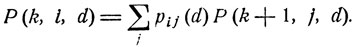
(11.9)
Оно является простым следствием формулы полной вероятности - на следующем шаге система с вероятностью pij (d), d = d(εi, k), переходит в одно из состояний εj, j = 1, 2,..., откуда приводится в множество Е с соответствующими вероятностями P(k+1, j, d).
В соотношении (11.9) при k = n-1 фигурирует вероятность
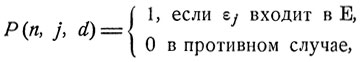
и, следовательно,
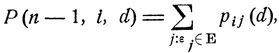
где суммирование идет по всем j, для которых εj входит в заданную совокупность Е. Очевидно, вероятность Р (n-1, i, d) зависит лишь от выбора одного-единственного значения управляющего параметра d(εi, n-1). Определим d° как точку максимума функции
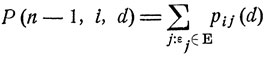
от параметра d, пробегающего множество D:
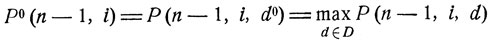
(11.10)
(здесь и в дальнейшем предполагается, что рассматриваемые функции от d достигают максимума). Ясно, что для каждой пары (εi, n-1) будет свое значение d0 = d0(εi, n-1), i = 1, 2,...
При k = n-2 формула (11.9) дает следующее соотношение:
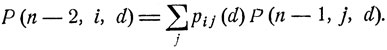
Здесь вероятности pij(d) зависят лишь от значений d = d (εi, n-2) решающей функции d = d(x, t), а вероятности Р(n-1, j, d) - лишь от исходных значений d = d(εj, n-1) этой функции. Если "подправить" решающую функцию d = d(x, t), заменив исходные значения d(εj, n-1) на определенные ранее значения d0(εj, n-1), то от этого соответствующие вероятности Р (n-1, j, d) увеличатся до максимально возможных значений Р0(n-1, j), что приведет к увеличению вероятности Р (n-2, j, d) до значения
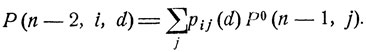
(11.11)
Зависимость от управляющей функции d = d(x, t) здесь проявляется лишь через зависимость переходных вероятностей pij(d) от управляющего параметра d = d(εi, n-2). Определим точку d0 как точку максимума функции от параметра d, пробегающего множество D:
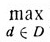 P(n-2, i, d)(11.12)
P(n-2, i, d)(11.12)Очевидно, для каждой пары (ε, n - 2) будет свое значение d = d (εi, n-2), i = 1, 2, ... Ясно, что если решающая функция d = d(x, t) при х = ε1, ε2, ... и t = n-2, n-1 принимает определенные выше значения d0(x, t), то вероятности P(k, i, d) при k = n-2, n-1 и всех i = 1, 2,... принимают максимально возможные значения P0(k, i).
Отправляясь от решающей функции d = d(x, t) такой, что
при всех х = ε1, ε2, ... и t = n-2, n-1, переходим затем к следующему соотношению:
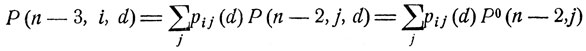
и определяем точку d0 = d0 (εi, n-3) максимума вероятности P(n-3, i, d) как функции от параметра d. Затем, так же как и ранее, "подправляем" решающую функцию d = d(x,t), определяя при t = n-3 ее значения формулой (11.13) для всех х = ε1, ε2, ...
Продолжая этот процесс, можно последовательно найти оптимальную решающую функцию d = d0(x, t), x = ε1, ε2, ..., t = 0, 1, ... , при которой вероятность P(d) = P(0, i, d), отвечающая начальному положению ξ(0) = εi, достигает своего максимального значения. На k-м шаге этого последовательного процесса соответствующее значение d0 = d0(εi, n-k) определяется как точка максимума функции
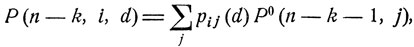
(11.14)
где Р0(k, i) суть максимально возможные значения рассматриваемых вероятностей Р (k, i, d); k = 0, 1, ... , n; i = 1, 2, ... Соотношение
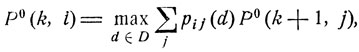
(11.15)
лежащее в основе описанного выше метода нахождения оптимальной решающей функции d0 = d0(x, t), называется уравнением Беллмана.
Пример. Пусть имеются два возможных состояния ε1 и ε2, причем в зависимости от управляющего параметра d переходные вероятности могут непрерывно меняться в пределах α1≤p11(d)≤β1, α2≤p21(d)≤β2. Как выглядит оптимальное управление, если требуется, чтобы в определенный момент (скажем, через два шага) система была в состоянии ε1?
В этом случае
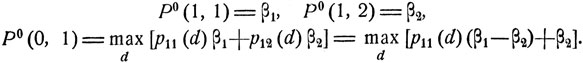
Видно, что, отправляясь из состояния ε1 следует выбрать максимальной переходную вероятность р11, если β1≥β2 (положив p11 = β1), И выбрать максимальной переходную вероятность р12 = 1-р11, если β1≤β2 (положив р11 = α1). Аналогично выглядит оптимальное решение для начального состояния ε2.
Задача о наилучшем выборе (см. п. 1 § 3). Рассмотрим описанную ранее процедуру выбора и отвечающий ей марковский случайный процесс с переходными вероятностями рij вида (см. стр. 76):
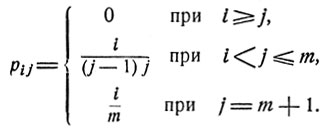
Выбор ξ(k)-го предмета можно интерпретировать как остановку соответствующего процесса 
В каждом из состояний ε1, ... , εm наблюдатель решает, остановить или продолжать процесс выбора. Первому решению, принятому в состоянии εi, формально соответствуют переходные вероятности pij вида
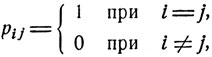
а второму решению - переходные вероятности, указанные ранее. Перед нами схема управляемого марковского процесса, переходные вероятности рij которого меняются в зависимости от решения наблюдателя. Управляющий параметр d здесь принимает два значения, скажем 0, что означает остановку процесса в соответствующем состоянии, и 1, что означает принятие противоположного решения. Зависимость переходных вероятностей pij = pij(d) указана выше. Каждая процедура выбора описывается некоторой решающей функцией d = d(x), х = ε1, ... , εm, которая предусматривает, в каком состоянии х следует продолжать процесс выбора, а в каком следует его прекратить и остановиться на последнем из осмотренных предметов. Задача состоит в том, чтобы найти такую процедуру выбора, такую решающую функцию d = d(x), х = ε1, ... , εm, чтобы вероятность выбрать абсолютно наилучший предмет была бы максимальной. Эта вероятность есть
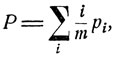
(11.16)
где i/m - вероятность того, что 1-й предмет будет наилучшим, pi - вероятность того, что процесс будет остановлен именно в состоянии εi, а суммирование происходит по всем тем состояниям εj, в которых, согласно решающей функции d = d(x), предписывается остановка процесса. Эта вероятность зависит от выбранной решающей функции d = d(x).
Для нахождения оптимальной решающей функции d0 = d0(x) рассмотрим вероятности P(k, d) выбрать наилучший предмет при условии, что число осмотренных до него предметов не меньше k, т. е. при условии, что рассматриваемый процесс на некотором шаге будет в состоянии εk. Согласно формуле полной вероятности
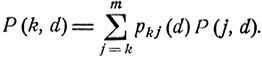
(11.17)
Очевидно, если процесс будет в состоянии εm, то m-й предмет и является наилучшим, так что оптимальным значением d = d0(εm) решающей функции d = d (х) является d0 (εm) = 0, при котором P(m,d) = 1. Из соотношений (11.16), (11.17) получаем, что при k = m-1 вероятность наилучшего выбора при значении d(εm) = 1 есть
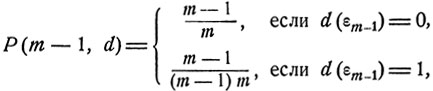
откуда видно, что оптимальным значением d = d0(εm-1) решающей функции d = d(x) является d0(εm-1) = 0. При этом 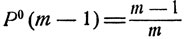 есть максимально возможное значение вероятности Р(m-1, d), зависящей от решающей функции d = d (х).
есть максимально возможное значение вероятности Р(m-1, d), зависящей от решающей функции d = d (х).
Предположим, что при x = εk, ... , εm оптимальные значения решающей функции d = d(x) все равны 0, что соответствует остановке процесса в состояниях εk, ... , εm. Каково предшествующее оптимальное значение d0(εk-1)?
Очевидно, если процесс останавливается в любом из состояний x = εk, ... , εm, то, как следует из соотношений (11.16), (11.17), вероятность наилучшего выбора при условии, что будет осмотрено не менее k-1 предметов, есть
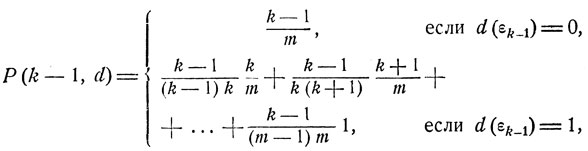
откуда видно, что оптимальное значение d = d0(εk-1) решающей функции d = d(x) есть
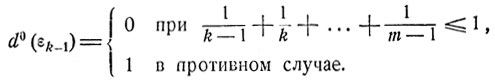
(11.18)
Легко видеть, что оптимальная решающая функция d = d(x) имеет следующую структуру:

где m0 - некоторое число. При оптимальном выборе следует продолжать процесс осмотра до тех пор, пока не попадется предмет с номером k≤m0, наилучший среди всех ранее осмотренных предметов. На этом k-м по счету предмете и следует остановить свой выбор. Согласно (11.18) число m0 есть наибольшее натуральное число, для которого
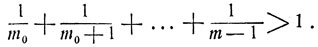
Нетрудно установить, что при больших m это число m0 приблизительно равно m/e, e = 2,78 ...
|
ПОИСК:
|
При копировании материалов проекта обязательно ставить ссылку на страницу источник:
http://mathemlib.ru/ 'Математическая библиотека'