ДИСПЕРСИОННЫЙ АНАЛИЗ
ДИСПЕРСИОННЫЙ АНАЛИЗ в математической статистике - статистический метод, предназначенный для выявления влияния отдельных факторов на результат эксперимента, а также для последующего планирования аналогичных экспериментов. Первоначально Д. а. был предложен Р. Фишером [1] для обработки результатов агрономия, опытов по выявлению условий, при к-рых испытываемый сорт сельскохозяйственной культуры дает максимальный урожай. Современные приложения Д. а. охватывают широкий круг задач экономики, социологии, биологии и техники и трактуются обычно в терминах статистич. теории выявления систематич. различий между результатами непосредственных измерений, выполненных при тех или иных меняющихся условиях.
Если значения неизвестных постоянных a1, ... , аI могут быть измерены с помощью различных методов или измерительных средств M1, ... , MJ, и в каждом случае систематич. ошибка bij может, вообще говоря, зависеть как от выбранного метода Mj, так и от неизвестного измеряемого значения аi, то результаты таких измерений представляют собой суммы вида
xijk = ai + bij + yijk, i = 1, ..., I; j = 1, ..., J, k = 1, ..., K,
где K' - количество независимых измерений неизвестной величины аi методом Mj, a yijk - случайная ошибка к-то измерения величины аi методом Мj (предполагается, что все yijk - независимые одинаково распределенные случайные величины, имеющие нулевое математич. ожидание: ∃yijk = 0). Такая линейная модель наз. двухфакторной схемой Д. а.; первый фактор - истинное значение измеряемой величины, второй - метод измерения, причем в данном случае для каждой возможной комбинации значений первого и второго факторов осуществляется одинаковое количество K независимых измерений (это допущение для целей Д. а. не является существенным и введено здесь лишь ради простоты изложения).
Примером подобной ситуации могут служить спортивные соревнования I спортсменов, мастерство к-рых оценивается J судьями, причем каждый участник соревнований выступает K раз (имеет K «попыток»). В этом случае аi - истинное значение показателя мастерства спортсмена с номером i, bij - систематич. ошибка, вносимая в оценку мастерства i-го спортсмена судьей с номером j, хijk - оценка, выставленная j-м судьей i-му спортсмену после выполнений последним k-й попытки, а уijk - соответствующая случайная погрешность. Подобная схема типична для так наз. субъективной экспертизы качества нескольких объектов, осуществляемой группой независимых экспертов. Другой пример -статистич. исследование урожайности сельскохозяйственной культуры в зависимости от одного из I сортов почвы и J методов ее обработки, причем для каждого сорта i почвы и каждого метода обработки с номером j осуществляется k независимых экспериментов (в этом примере bij - истинное значение урожайности для i-го сорта почвы при j-м способе обработки, хijk - соответствующая экспериментально наблюдаемая урожайность в k-м опыте, a yijk - ее случайная ошибка, возникающая из-за тех или иных случайных причин; что же касается величин аi, то в агрономич. опытах их разумно считать равными нулю).
Положим сij = аi + bij, и пусть сi*, с*j и с** - результаты осреднений сij по соответствующим индексам, т. е.
ci* = 1/J ∑j cij,
Пусть, кроме того, α = c**, βi = ci* - с**, γi = с*j - с** и δij = cij - ci* - c*j + c**. Идея Д. а. основана на очевидном тождестве
cij = α + βi + γi + δij, i = 1, ..., I, j = 1, ..., J. (1)
Если символом (сi) обозначить вектор размерности IJ, получаемый из матрицы ||сij|| порядка I × J с помощью какого-либо заранее фиксированного способа упорядочивания ее элементов, то (1) можно записать в виде равенства
(cij) = (αij) + (βij) + (γij) + (δij), (2)
где все векторы имеют размерность IJ, причем αij = α, βij = βi, γij = γj. Так как четыре вектора в правой части (2) ортогональны, то αij = α - наилучшее приближение функции сij от аргументов i и j постоянной величиной [в смысле минимальности суммы квадратов отклонений
∑ij(cij - α)2]. В том же смысле αij + βij = α + β - наилучшее приближение cij функцией, зависящей лишь от i, αij + γij = α + γj - наилучшее приближение сij функцией, зависящей лишь от j, а αij + βij + γij = α + βi + γj - наилучшее приближение сij суммой функций, из к-рых одна (напр., α + βi) зависит лишь от i, а другая - лишь от j. Этот факт, установленный Р. Фишером (см. [1]) в 1918, позднее послужил основой теории квадратичных приближений функций.
В примере, связанном со спортивными соревнованиями, функция δij выражает «взаимодействие» i-го спортсмена и j-го судьи (положительное значение δij означает «подсуживание», т. е. систематич. завышение j-м судьей оценки мастерства i-го спортсмена, а отрицательное значение δij означает «засуживание», т. е. систематич. снижение оценки). Равенство всех δij нулю - необходимое требование, к-рое надлежит предъявлять к работе группы экспертов. В случае же агрономич. опытов такое равенство рассматривается как гипотеза, подлежащая проверке по результатам экспериментов, поскольку основная цель здесь - отыскание таких значений i и j, при к-рых функция (1) достигает максимального значения. Если эта гипотеза верна, то
max сij = α + max βi + max γj,
и значит, выявление наилучших «почвы» и «обработки» может быть осуществлено раздельно, что приводит к существенному сокращению числа экспериментов (напр., можно при каком-либо одном способе обработки испытать все I сортов «почвы» и определить наилучший сорт, а затем на этом сорте опробовать все J способов «обработки» и найти наилучший способ; общее количество экспериментов с повторениями будет равно (I + J) K). Если же гипотеза {все δij = 0} неверна, то для определения max cij необходим описанный выше «полный план», требующий при K повторениях IJK экспериментов.
В ситуации спортивных соревнований функция γij = γj может трактоваться как систематич. ошибка, допускаемая j-м судьей по отношению ко всем спортсменам. В конечном счете γj - характеристика «строгости» или «либеральности» j-го судьи. В идеале хотелось бы, чтобы все γj были нулевыми, но в реальных условиях приходится мириться с наличием ненулевых значений γj и учитывать это обстоятельство при подведении итогов экспертизы (напр., за основу сравнения мастерства спортсменов можно принять не последовательности истинных значений α + β1 + γj, ..., α + βI + γj, а лишь результаты упорядочиваний этих чисел по их величине, поскольку при всех j = 1, ..., J такие упорядочивания будут одинаковыми). Наконец, сумма двух оставшихся функций αij + βij = α + βi зависит лишь от i и поэтому может быть использована для характеризации мастерства i-го спортсмена. Однако здесь нужно помнить, что α + βi = ai + bi* ≠' ai. Поэтому упорядочивание всех спортсменов по значениям α + βi (или по α + βi + γj при каждом фиксированном j) может не совпадать с упорядочиванием по значениям ai. При практической обработке экспертных оценок этим обстоятельством приходится пренебрегать, так как упомянутый полный план экспериментов не позволяет оценивать отдельно аi и bi*. Таким образом, число α + βi = аi + bi, характеризует не только мастерство i'-го спортсмена, но и в той или иной мере отношение экспертов к этому мастерству. Поэтому, напр., результаты субъективных экспертных оценок, осуществленных в разное время (в частности, на нескольких Олимпийских играх), едва ли можно считать сопоставимыми. В случае же агрономич. опытов подобные трудности не возникают, поскольку все ai = 0 и значит, α + βi = bi*.
Истинные значения функций α, βi, γi и δij неизвестны и выражаются в терминах неизвестных функций сij. Поэтому первый этап Д. а. заключается в отыскании статистич. оценок для сij по результатам наблюдений xijk. Несмещенная и имеющая минимальную дисперсию линейная оценка для сij выражается формулой
ĉij = xij* = 1/K ∑k Xijk.
Так как α, βi, γj и δij - линейные функции от элементов матрицы ||сij||, то несмещенные линейные оценки для этих функций, имеющие минимальную дисперсию, получаются в результате замены аргументов сij соответствующими оценками, с̂ij, т. е.
α̂ = x***, β̂i = xi** - x***, γ̂j = x*j* - x***, δ̂ij = xij* - xi** - x*j* + x***,
причем случайные векторы (α̂ij), (β̂ij), (γ̂ij) и (δ̂ij), определенные так же, как введенные выше (αij), (βij), (γij) и (δij), обладают свойством ортогональности, и значит, они представляют собой некоррелированные случайные векторы (иными словами, любые две компоненты, принадлежащие разным векторам, имеют нулевой коэффициент корреляции). Кроме того, любая разность вида
xijk - xij* = xijk - ĉij
некоррелирована с любой из компонент этих четырех векторов. Рассмотрим пять совокупностей случайных
величин {xijk}, {xijk - xij*}, {β̂i}, {γ̂j} и {δ̂ij}. Так как xijk - xij* = yijk - ij*, β̂i = βi + (yi** - y***), γ̂i = γj + (y*j* - y***), δ̂ij = δij + (yij* - yi** - y*j* + y***),
то дисперсии эмпирич. распределений, соответствующих указанным совокупностям, выражаются формулами
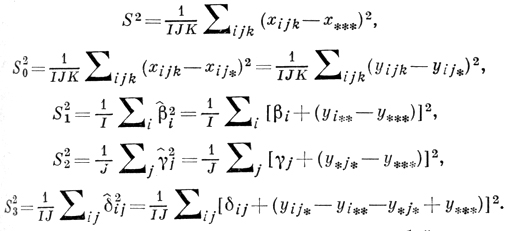
Эти эмпирич. дисперсии представляют собой суммы квадратов случайных величин, любые две из к-рых не-коррелированы, если только они принадлежат разным суммам; при этом относительно всех yijk справедливо тождество
S2 = S20 + S21 + S22 + S23,
объясняющее происхождение термина «Д. а.». Пусть I, J, K > 2 и пусть
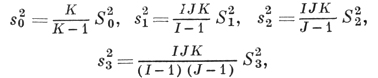
в таком случае
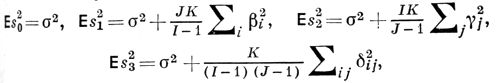
где σ2 - дисперсия случайных ошибок yijk.
На основе этих формул и строится второй этап Д. а., посвященный выявлению влияния первого и второго факторов на результаты эксперимента (в агрономич. опытах первый фактор - сорт «почвы», второй - способ «обработки»). Напр., если требуется проверить гипотезу отсутствия «взаимодействия» факторов, к-рая выражается равенством ∑ij δ2ij = 0, то разумно вычислить дисперсионное отношение s23/s20 = F3. Если это отношение значимо отличается от единицы, то проверяемая гипотеза отвергается. Точно так же для проверки гипотезы ∑jγ2j = 0 полезно отношение s22/s20 = F2, к-рое надлежит также сравнить с единицей; если при этом известно, что ∑ijδ2ij = 0, то вместо F2 целесообразно сравнить с единицей отношение
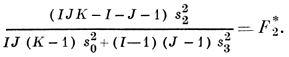
Аналогичным образом можно построить статистику, позволяющую дать заключение о справедливости или ложности гипотезы ∑i β2i = 0.
Точный смысл понятия значимого отличия указанных отношений от единицы может быть определен лишь с учетом закона распределения случайных ошибок уijk. В Д. а. наиболее обстоятельно изучена ситуация, в к-рой все yijk распределены нормально. В этом случае (α̂ij), (β̂ij), (γ̂ij), (δ̂ij) -независимые случайные векторы, а s20, s21, s22, s23 - независимые случайные величины, причем отношения
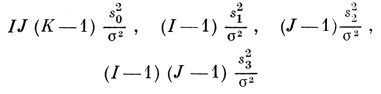
подчиняются нецентральным распределениям хи-квад-рат с fm степенями свободы и параметрами нецентральности λm, m = 0, 1, 2, 3, где
f0 = IJ(K - 1), f1 = I - 1, f2 = J - 1, f3 = (I - J)(J - 1); λ0 = 0, λ1 = JK ∑i β2i/σ2, λ2 = IK ∑j γ2j/σ2, λ3 = K ∑ij δ2ij/σ2.
Если параметр нецентральности равен нулю, то нецентральное распределение хи-квадрат совпадает с обычным распределением хи-квадрат. Поэтому в случае справедливости гипотезы λ3 = 0 отношение s23/s20 = F3 подчиняется F-распределению (распределению дисперсионного отношения) с параметрами f3 и f0. Пусть х - такое число, для к-рого вероятность события {F3 > x} равна заданному значению ε, называемому уровнем значимости (таблицы функции х = х(ε; f3, f0) имеются в большинстве пособий по математич. статистике). Критерием для проверки гипотезы λ3 = 0 служит правило, согласно к-рому эта гипотеза отвергается, если наблюдаемое значение F3 превышает x; в противном случае гипотеза считается не противоречащей результатам наблюдений. Аналогичным образом конструируются критерии, основанные на статистиках F2 и F*2.
Дальнейшие этапы Д. а. существенно зависят не только от реального содержания конкретной задачи, но также и от результатов статистич. проверки гипотез на втором этапе. Напр., в условиях агрономич. опытов справедливость гипотезы λ3 = 0, как указано выше, позволяет более экономно спланировать аналогичные дальнейшие эксперименты (если помимо гипотезы λ3 = 0 справедлива также и гипотеза λ2 = 0, то это означает, что урожайность зависит лишь от сорта «почвы», и поэтому в дальнейших опытах можно воспользоваться схемой однофакторного Д. а.); если же гипотеза λ3 = 0 отвергается, то разумно проверить, нет ли в данной задаче неучтенного третьего фактора? Если сорта «почвы» и способы ее «обработки» варьировались не в одном и том же месте, а в различных географич. зонах, то таким фактором могут быть климатич. или географич. условия, и «обработка» наблюдений потребует применения трехфакторного Д. а.
В случае экспертных оценок статистически подтвержденная справедливость гипотезы λ3 = 0 дает основание для упорядочивания сравниваемых объектов (напр., спортсменов) по значениям величин α̂ + α̂i, i = 1, ..., I. Если же гипотеза λ3 = 0 отвергается (в задаче о спортивных соревнованиях это означает статистич. обнаружение «взаимодействия» нек-рых спортсменов и судей), то естественно попытаться перевычислить все результаты заново, предварительно исключив из рассмотрения xijk с такими парами индексов (i, j), для к-рых абсолютные значения статистич. оценок δij превышают нек-рый заранее установленный допустимый уровень. Это означает, что из матрицы ||xij*|| вычеркиваются нек-рые элементы, и значит, план Д. а. становится неполным.
Модели современного Д. а. охватывают широкий круг реальных экспериментальных схем (напр., схемы неполных планов, со случайно или неслучайно отобранными элементами xij*). Соответствующие этим схемам статистич. выводы во многих случаях находятся в стадии разработки. В частности, еще (к 1978) далеки от окончательного решения те задачи, в к-рых результаты наблюдений xijk = cij + yijk не являются одинаково распределенными случайными величинами; еще более трудная задача возникает в случае зависимости величин xijk. Неизвестно решение проблемы выбора факторов (даже в линейном случае). Суть этой проблемы заключается в следующем: пусть с = с(u, v) - непрерывная функция и пусть u = u(z, w) и v = v(z, w) - какие-либо линейные функции от переменных z и w. Фиксируя значения z1, ..., zI и w1, ..., wJ, можно при каждом заданном выборе линейных функций u и v определить сij формулой
сij = с[u(zi, wj), v(zi, wj)]
и построить Д. а. этих величин по результатам соответствующих наблюдений хijk. Проблема заключается в отыскании таких линейных функций u и v, к-рым соответствует минимальное значение суммы квадратов ∑ij δ2ij, где
δij = cij - ci* - c*j + c**
(предполагается, что функция с(u, v) неизвестна). В терминах Д. а. эта проблема сводится к статистич. отысканию таких факторов z = z(u, v) и w = w(u, v), к-рым соответствует «наименьшее взаимодействие».
Лит.: [1] Fisher R. A., Statistical methods for research workers, Edinburgh, 1925; [2] Шеффе Г., Дисперсионный анализ, пер. с англ., М., 1963; [3] Xальд А., Математическая статистика с техническими приложениями, пер. с англ., М., 1956; [4] Снедекор Дж. У., Статистические методы в применении к исследованиям в сельском хозяйстве и биологии, пер. с англ., М., 1961.
Л. Н. Большев.
Источники:
- Математическая энциклопедия: Гл. ред. И. М. Виноградов, т. 2 Д - Коо.-М.: «Советская Энциклопедия», 1979.-1104 стб., ил.
|
ПОИСК:
|
При копировании материалов проекта обязательно ставить ссылку на страницу источник:
http://mathemlib.ru/ 'Математическая библиотека'